
Uppdatering 2015-09-19: En uppföljning till detta inlägg med en vidare analys av problemet, finns nu här.
Jag har just spenderat hela dagen med att felsöka ett problem av den lite ovanligare sorten, och tänkte här återge i stora drag hur jag gick tillväga och vad jag hittade under det arbetet. Är man intresserad av felsökningsmetodik på lite djupare nivåer i SCCM 2012, där man tack och lov rätt sällan behöver pilla runt (och absolut inte SKA pilla runt om man inte är väldigt säker på vad man gör), så kan detta inlägg vara intressant att läsa. Men framför allt är också slutsatsen och upptäckten av den faktiska felorsaken intressant att känna till för alla. Jag lärde mig själv en del nytt som jag tar med mig i bagaget för framtiden.
Bakgrund
Under förra året gjorde jag en nyinstallation av SCCM 2012 hos en kund, som sedan under 2015 fortsatt införandet i delar av sin organisation. I somras råkade av misstag en ”AD user discovery” ske mot en mot en plats i AD som innehåller användarkonton som inte ska hanteras i SCCM. Det var ingen liten mängd utan rörde sig om flera hundratusentals konton. Teoretiskt är detta inget problem i sig då det ”bara” är att radera dessa konton i SCCM. Men då det rör sig om sådana här mängder, i en miljö som heller inte är dimensionerad för detta, så upptäcker man hur lång tid det faktiskt tar att radera ett objekt i SCCM. Det skulle helt enkelt ta alldeles för lång tid att rensa all denna information, så det beslutades istället att en återläsning av backupen skulle ske.
Databasbackuper kördes varje natt och man hade inga förändringar som skulle gå förlorade, så tanken var att detta skulle gå oändligt mycket snabbare än att försöka rensa ur databasen.
Sagt och gjort, databasen lästes tillbaka och vips var man av med över 300 000 konton som man inte ville ha på en bråkdel av tiden jämfört med att radera allting. Här ska noteras att enbart databasen lästes tillbaka, en ”site recovery” kördes inte. Enligt dokumentationen ska egentligen alltid en site recovery köras, men det är egentligen oklart varför och dokumenationen är egentligen ganska luddig. I SCCM 2012 finns t.ex. inte längre någon ”site control fil” och det är numera supportat att göra en site recovery med enbart en databasbackup från t.ex. ett SQL Maintenance Job. All relevant information och konfiguration ska finnas i databasen, så att återställa just bara databasen kan man ju tycka räcker. Vad gör ”site recovery”-processen i övrigt för magi som gör att man bör köra den? Det framgår inte i någon dokumentation, och här skulle jag säga råder en viss förvirring i världen.
Hur som helst, här återläste man alltså enbart databasen. Allting verkade frid och fröjd, allt ”lyste grönt” och fungerade som det skulle. Tills man började köra ”OS deployment” och rulla burkar.
Själva installationerna gick precis som vanligt utan problem, men man använder också variabler på både collections och på datorobjekten för att dynamiskt kontrollera en rad olika saker i installationen. Vad man nu upptäckte var att datorvariablerna inte längre fungerade, och ignorerades helt och hållet av task sequencen.
Analys
För att felsöka problemet fick jag först börja ”från början”, då jag själv inte varit med vid återläsningen från backup och inte sett miljön på länge. Jag började alltså med en enkel hälsokontroll för att se om det fanns några allmänna fel eller problem, eller tecken på att något gått fel vid återläsningen. Allting tycktes dock vara ett praktexempel på en fungerande miljö utan några konstigheter.
Då just problem med datorvariabler och OSD har varit en känd bugg tidigare så kontrollerade jag också snabbt att den hotfixen inte längre var applicerbar (den byter bara ut en liten dll-fil), och så var inte fallet. Det hade också varit konstigt då versionsnivån var R2 SP1 (dock utan CU1), där denna fix för länge sen ingår. Service packen hade också installerats efter återläsningen från backup, vilket annars är en bra metod för att lösa många problem då i princip de flesta delar på hela site servern ominstalleras och återställs. Men problemet kvarstod alltså.
Jag fortsatte sedan med att skruva upp loggningen till maxnivå på SMSTS.log på klienten (en bra artikel för hur man gör detta och ändrar maxstorleken på loggen, kan man läsa här). I loggen kunde jag mycket riktigt utläsa ”Found 0 machine variables” och att någon policy för datorvariabler aldrig ens försökte laddas ned. Däremot fungerade collection variabler utan problem. Något annat intressant fanns inte här, men detta räckte för att visa att det helt enkelt inte fanns någon policy för datorvariabler att hämta på management pointen. Det kändes alltså tydligt som ett serverproblem och inte ett klientproblem.
Jag aktiverade därefter debug logging på management pointen och började gå igenom de olika MP-loggarna, och matcha vad som hände där samtidigt som klienten efterfrågade sin policy. Kort sagt fanns inget intressant att hitta om problemet i dessa loggar. Jag såg inga tecken på problem i management pointen, och kunde helt enkelt inte se några spår av en policy med datorvariabler hämtats från databasen.
Nästa steg i kedjan blev alltså att börja undersöka själva databasen, och den process som genererar policies som sedan levereras till MPn. Den komponent i SCCM som ansvarar för detta heter SMS_POLICY_PROVIDER och har en loggfil som heter policypv.log. Jag började alltså gräva i denna loggfil, samt även i loggen smsdbmon.log för att se vad hände i databasen.
Jag började skapa variabler på datorobjekt, både i den riktiga miljön samt i min egen testmiljö, där allting fungerade som det ska, och jämförde resultaten.
Så fort en variabel skapas kan följande utläsas i smsdbmon.log:
![]()
Ok, så tabellen MEP_MachineExtendedProperties har uppdaterats. Detta är också vad som är förväntat, och detta skedde utan problem, likadant i både problem-miljön och min testmiljö.
Det som ska ske härnäst är att en ny policy ska genereras för datorn som har fått variabeln, och denna policy ska alltså innehålla variabeln och dess värde. Detta ser man tydligt i policypv.log, och så här ser det ut i min testmiljö när det fungerar som det ska:
![]()
Det vi ser här är ett urval ur loggen som visar hur en ny policy som innehåller ”machine extended properties”, vilket är lika med datorvariabler, har genererats för en dator med ett visst ”machine ID” och GUID. En snabb koll i konsolen, alternativt ”Get-CMDevice -Name MinTestDator” visar att detta ID och GUID mycket riktigt hör till den dator där jag skapade variabeln.
I problem-miljön såg det dock lite annorlunda ut. Samma saker sker fram till raden i loggen som börjar med ”MEP-Querying MV for rowversion...” men där det sedan ska returneras en ny policy, så var det här helt tomt. Ingen policy med ”machine extended properties” kom tillbaka, och SMS_POLICY_PROVIDER fortsatte glatt att generera policy för allt annat (applikationsinstallationer, device settings, osv).
Loggraden ”MEP-Querying MV for rowversion...” ser i sin helhet ut så här:
|
1 |
MEP-Querying MV for rowversion > 0x00000000001CE420 AND MachineID in (SELECT ItemKey FROM System_DISC WHERE SMS_Unique_Identifier0 IS NOT NULL AND ((16777216 < ItemKey AND ItemKey < 33554431) OR (1 <= ItemKey AND ItemKey <= 16777215))) |
Det körs alltså en query i databasen, och därefter ska policyn som innehåller variabeln returneras. Hmm, kunde det vara så att denna query inte gav önskat resultat? Det var dags att på allvar titta ned i databasen.
Först lite bakgrund till hur det SKA se ut i databasen när allting fungerar som det ska.
När man skapar en variabel på en dator så uppdateras följande tre tabeller i databasen:
MEP_MachineVariables
MEP_MachineExtendedProperties
MEP_MachinePolicies
Jag testade att skapa variabeln ”MinTestVariabel” på min testmaskin ”testar3” som har Machine ID 16777235, och tittar i den första tabellen.
|
1 |
select * from MEP_MachineVariables |
![]()
Vi kan tydligt se att variabeln har skapats (värdet är dock ”scramblat” och går inte att läsa i klartext).
Nästa tabell, MEP_MachineExtendedProperties, innehåller ingen information i sig, utan är bara en plats för att hålla reda på vilka datorobjekt som faktiskt har variabler definierade, och när en förändring av dessa görs.
|
1 |
select * from MEP_MachineExtendedProperties |
![]()
Återigen hittar vi en rad med min testdator, information om när ändringen gjordes, samt någonting som heter rowversion. Vi återkommer till detta.
När väl dessa båda tabeller är uppdaterade ska, om allt fungerar korrekt, en ny policy genereras för datorn som innehåller variabeln. Att så har skett ser vi i den sista tabellen.
|
1 |
select * from MEP_MachinePolicies |
![]()
Min testdator har dykt upp här, och i det här läget kan man alltså se i policypv.log att en ”MEP-policy” för datorn mycket riktigt hämtas.
I problem-miljön dök dock datorn bara upp i de två första tabellerna, men aldrig i den tredje. Ok, så variabeln lagras korrekt i databasen, och även den tidsstämplade informationen om att det faktiskt finns en variabel (i MEP_MachineExtendedProperties), men någon policy skapas tydligen aldrig. Det var dags att gå till botten med hur logiken i mekanismen som genererar denna policy faktiskt fungerar. Det var dags att göra en databas ”trace”.
För detta ändamål använder vi verktyget SQL Server Profiler vilket är ungefär motsvarigheten till Process Monitor i databasvärlden. Vi kan följa i realtid exakt vad som sker i databasen, vilka queries som görs, vilka transaktioner som sker. Precis som med Process Monitor blir det snabbt ett hav med information, och särskilt då det gäller en produktionsmiljö där det hela tiden sker saker. Det gäller alltså att veta ungefär vad man letar efter.
För att minska mängden information skapade jag ett filter: ApplicationName Like SMS_POLICY_PROVIDER
Detta då jag ju visste att det är denna komponent som genererar policies och att problemet därför måste ligga där, så med detta filter blev mängden hanterbar.
Genom att söka på ”MEP” fick jag ganska snabbt fram en hel del intressant information. Jag kunde se att det första som skedde var att följande query gjordes:
|
1 |
select MachineID,SourceSite,LocaleID,LastModificationTime,rowversion from MEP_MachineExtendedProperties where rowversion > 0x00000000001C8A7C AND MachineID in (SELECT ItemKey FROM System_DISC WHERE SMS_Unique_Identifier0 IS NOT NULL AND ((16777216 < ItemKey AND ItemKey < 33554431) OR (1 <= ItemKey AND ItemKey <= 16777215))) order by rowversion |
Aha, detta var ju samma query vi såg tidigare i policypv.log. Och mycket riktigt, efter denna query kunde jag i tracen se i min testmiljö steg för steg hur policyn skapades, men i problem-miljön hände ingenting. Så låt oss undersöka denna query.
Det den gör är kort och gott att leta fram alla datorer där en variabel har lagts till, tagits bort eller förändrats. Och denna information sparades ju i tabellen MEP_MachineExtendedProperties. Kör jag denna query manuellt så får jag mycket riktigt till svar just den dator där jag just skapat en variabel (i det här fallet min testdator ”testar3”).
Så logiken här är alltså att leta fram enbart de datorer där en förändring av en variabel har skett genom att titta i MEP_MachineExtendedProperties, därefter generera en policy för denna dator och spara information om detta i MEP_MachinePolicies.
I problem-miljön såg det ut så här:
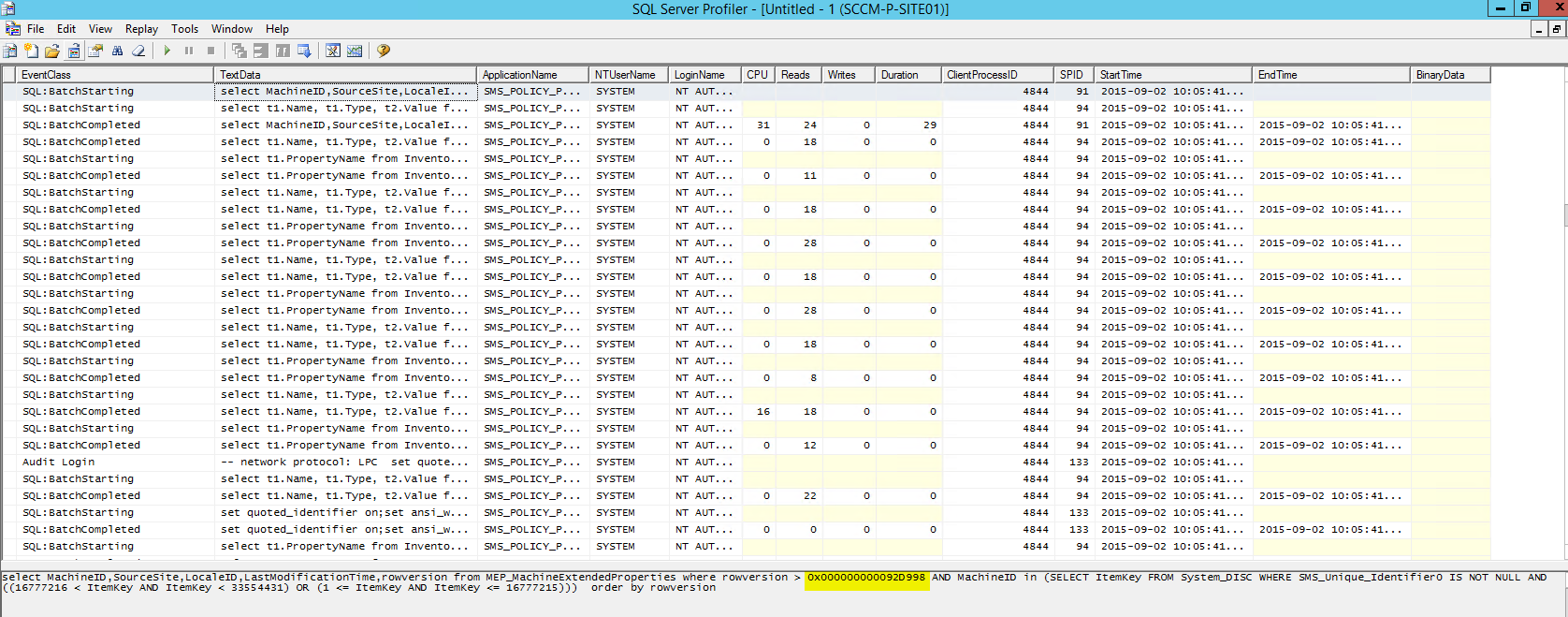
Alltså samma query här, men i den här miljön returneras inget svar vilket jag snabbt kan kontrollera genom att köra den manuellt. Så vad är problemet, varför hittas inte min dator där jag lagt till en variabel? Jag kunde ju se att min dator låg i tabellen MEP_MachineExtendedProperties precis som den ska, och det är ju där queryn ställer sin fråga. Låt oss återigen titta närmare på queryn. Den filtrerar resultatet genom att ställa villkoret att innehållet i kolumnen rowversion måste vara större än ett visst värde, som anges i hexadecimal form. Jag jämförde värdet i queryn med det högsta värdet som faktiskt fanns i tabellen, och upptäckte att värdet i queryn var över 4 miljoner högre än vad som fanns i tabellen. Så kort sagt, den frågar efter någonting som är otroligt mycket högre än vad som faktiskt finns, och får därför tillbaka ett tomt svar. Policy providern kommer tolka detta som att ingen dator har uppdaterat någon variabel och någon policy kommer därför heller inte att genereras. Logiskt, och nu börjar vi närma oss lösningen.
Så vad är då detta ”rowversion” och varför är värdet i queryn fel?
Enkelt förklarat används ”rowversion” för att spåra förändringar som sker i en databas, som en sorts versionshantering i tabellerna. Värdet är globalt för hela databasen men är frivilligt att använda i varje enskild tabell. Så fort en tabell innehåller en ”rowversion-kolumn” kommer den globala räknaren att öka med ett steg så fort en förändring sker i denna tabell. Mer detaljer finns att läsa på MSDN.
Nu är sista pusselbiten på plats för att förstå hur logiken fungerar med queryn ovan. Rowversion används alltså i tabellen MEP_MachineExtendedProperties för att hålla koll på varje gång en variabel läggs till, uppdateras eller tas bort. När så sker ska en ny policy genereras. Policy providern håller koll på senaste värdet för rowversion, och behöver därför bara ställa en fråga efter alla datorer som har ett högre värde för att på så vis få reda på vilka datorer som ska ha en ny policy.
Men varför trodde policy providern att det senaste rowversion-värdet var hela 4 miljoner högre än vad det verkliga värdet faktiskt var i databasen?
Hela problemet hade ju börjat efter en backup-återläsning av en SCCM-databas som innehöll ~300 000 färre objekt. När importen av alla dessa objekt skedde så motsvarade det tydligen ca 4 miljoner transaktioner i databasen, varpå rowversion ökades upp motsvarande. Efter återläsningen så återställdes detta värde till samma som det var innan hela importen, alltså ca 4 miljoner lägre.
Det var nu uppenbart att SCCM sparar detta värde även någonstans UTANFÖR databasen, och att vi därför fick detta glapp mellan vad policy providern trodde var den senaste förändringen, och vad som faktiskt stod i databasen. Så var kan detta tänka lagras?
Registret känns ju som en väldigt kvalificerad gissning, och nu råkade jag veta att de flesta SCCM-komponenter har en egen registernyckel under HKLM\Software\Microsoft\SMS\Components, och mycket riktigt så finns en nyckel där även för policy providern. Jag började med att titta där och fick jackpot direkt:
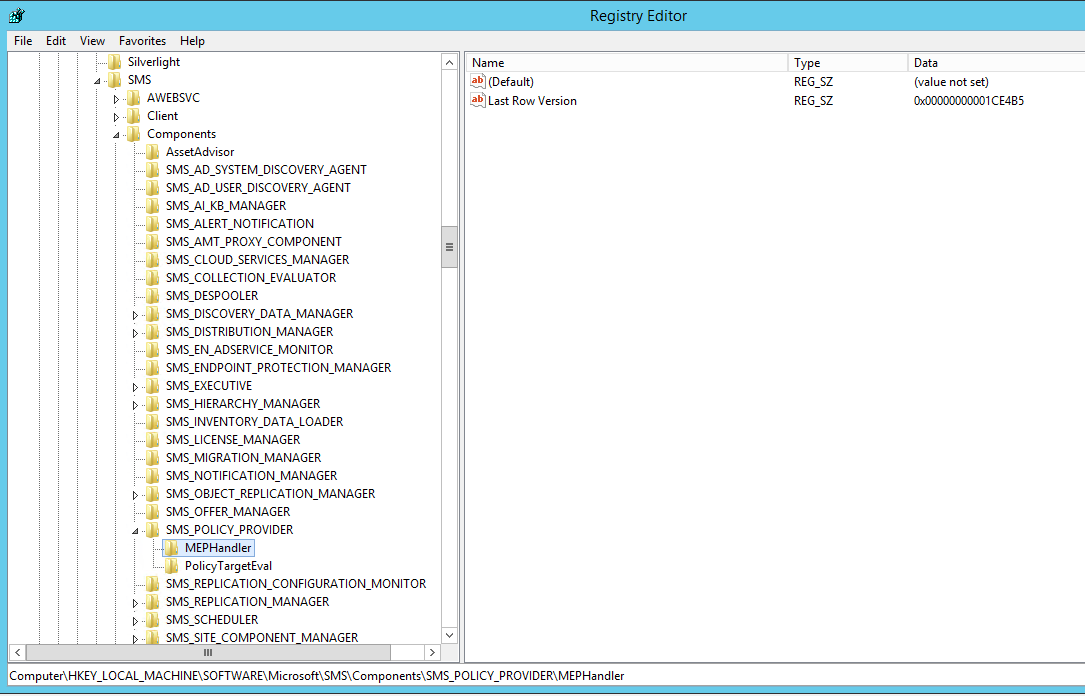
VOILA! Här står klart och tydligt nyckeln MEPHandler som har ett värde med namn ”Last Row Version”. Kan det vara så enkelt? Jag jämförde datat i det värdet, ett hexadecimalt tal, med värdet för rowversion i den query som jag tidigare sett i policypv.log och i SQL tracen, och det var såklart exakt samma värde. Här var alltså det gäckande talet som var 4 miljoner för högt och som gjorde att inga datorvariabel-förändringar fångades upp i databasen.
Lösningen? En snabb titt igen i MEP_MachineExtendedProperties och sortera efter just rowversion för att leta upp det högsta värdet i tabellen:
|
1 |
select * from MEP_MachineExtendedProperties order by rowversion |
Jag kopierade detta värde och klistrade in i registret och PANG så började allting att fungera perfekt igen.
Slutsats
Förutom att den här typen av felsökningsarbete är fantastiskt roligt, sådär som bara de nördigaste av de nördiga kan uppskatta, så lämnar dagens övningar ett par nya lärdomar och även ett frågetecken efter sig. Traditionellt har det i SCCM-världen alltid, fram till härom året, varit ett ”big no-no” att göra en återläsning på något annat sätt än från en backup gjord med det inbyggda backup-jobbet i SCCM. Det har alltså inte räckt att bara peka på en backup av databasen. Själv har jag haft lite svårt att vänja mig vid tanken på att man numera kan göra så.
Det inbyggda backupjobbet tar, förutom databasen, även med inboxarna och andra saker från filsystemet, samt även alla registernycklar. Och faktum är, jag dubbelkollade i min testmiljö nu ikväll, att just denna nyckel som innehåller ”last row version” tas med i den backupen. Så med andra ord, hade man använt den traditionella SCCM-backupen hade detta problem aldrig uppstått. Men när man återställer från en sådan backup så gör man å andra sidan också per definition en site recovery.
Men frågetecknet är detta: hade en site recovery fixat till problemet som här uppstod, och på något sätt synkat värdet i registret med databasen?
Jag vet inte, det får hamna på min att-göra-lista att prova i min testmiljö. Jag hoppas att så är fallet. Om inte, så är detta en brist i det fullt supportade scenariot att göra en återställning med enbart en databasbackup.
Det här är första gången jag ser en miljö läsas tillbaka på det här sättet, alltså att man bara lagt tillbaka databasen men struntat i site recovery. Men jag tror att det inte är helt ovanligt att så sker. På olika bloggar och forum runt om i världen nämns det ofta att backup i SCCM numera enbart handlar om databasen, och att det är den bästa metoden för då kan man använda ett SQL maintenance job eller DPM eller liknande, och därmed komprimera backupen och spara utrymme, och att allting är snabbare och bättre osv. Med andra ord börjar folk gå ifrån att använda det inbyggda backupjobbet i SCCM. Och jag kan tänka mig att många också gör en återläsning med just bara databasen. För allting finns ju där, och det funkar ju faktiskt. Dvs, förutom det problem som uppstod just i det här fallet. 🙂
Nu ska sägas att det är mycket osannolikt att det här scenariot uppstår, det här var förmodligen ett ganska unikt fall. Att man i en produktionsmiljö väljer att läsa tillbaka en backup som innehåller över 300 000 färre objekt hör knappast till det vanliga. Är det bara en liten differens mellan policy providerns räknare i registret och värdet i databasen, så äts den skillnaden upp ganska snabbt med alla transaktioner som sker hela tiden i databasen.
Kan det finnas andra saker som inte funkar när man återställer enbart databasen utan att också göra en site recovery? Säkert. Slutsatsen måste därför bli att verkligen följa site recovery wizarden i alla lägen.
En sista fundering från mig. VARFÖR i herrans namn sparas detta värde i registret, och inte i databasen? Varför får helt enkelt inte policy providern istället en egen liten tabell där den kan skriva detta och underhålla detta värde? Detta är i min mening ett designfel från utvecklarna. Jag kan i alla fall inte föreställa mig något bra skäl till att lagra en databaspekare utanför databasen.
1 kommentar
Imponerande
Kul att du delar med dig av hela scenariot